5.1 Raft 基础
一个 Raft 集群包括若干服务器;对于一个典型的5服务器集群,该集群能够容忍2台机器不能正常工作,而整个系统保持正常。在任意的时间,每一个服务器一定会处于以下三种状态中的一个:Leader、Candidate、Follower。在正常情况下,只有一个服务器是Leader,剩下的服务器是 Follower。Follower 是被动的:它们不会发送任何请求,只是响应来自 Leader 和 Candidate 的请求。Leader来处理所有来自客户端的请求(如果一个客户端与 Follower 进行通信,Follower 会将信息发送 Leader)。Candidate 是用来选取一个新的 Leader 的,这一部分会在 5.2节进行阐释。图-4 阐述了这些状态,以及它们之间的转换;它们的转换会在下面进行讨论。
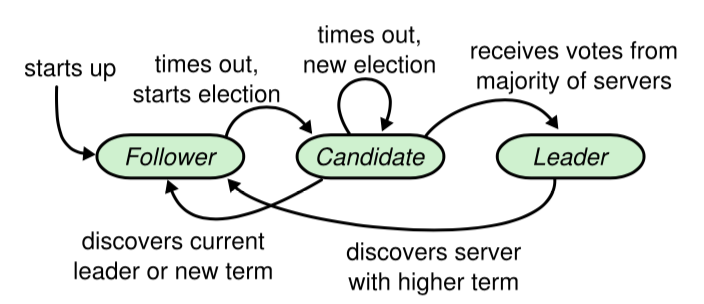
图-4:服务器的状态。Follower 只响应其他服务器的请求。如果 Follower 没有收到任何消息,它会成为一个 Candidate 并且开始一次选举。收到大多数服务器投票的 Candidate 会成为新的 Leader。Leader 在它们宕机之前会一直保持 Leader 的状态。
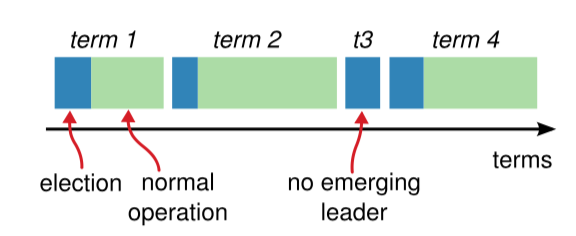
图-5:时间被分为一个个的任期(Term),每一个任期的开始都是 Leader 选举。在成功选举之后,一个 Leader 会在任期内管理整个集群。如果选举失败,该任期就会因为没有 Leader 而结束。这个转变会在不同的时间的不同服务器上观察到。
如 图-5 所示,Raft 算法将时间划分成为任意不同长度的任期(Term)。任期用连续的数字进行表示。每一个任期的开始都是一次选举,就像 5.2节所描述的那样,一个或多个 Candidate 会试图成为Leader。如果一个 Candidate 赢得了选举,它就会在该任期的剩余时间担任 Leader。在某些情况下,选票会被瓜分,有可能没有选出 Leader,那么,将会开始另一个任期,并且立刻开始下一次选举。Raft 算法保证在给定的一个任期最少要有一个 Leader。
不同的服务器可能会在任期内观察到多次不同的状态转换,在某些情况下,一台服务器可能看不到一次选举或者一个完整的任期。任期在 Raft 中充当逻辑时钟的角色,并且它们允许服务器检测过期的信息,比如过时的 Leader。每一台服务器都存储着一个当前任期的数字,这个数字会单调的增加。当服务器之间进行通信时,会互相交换当前任期号;如果一台服务器的当前任期号比其它服务器的小,则更新为较大的任期号。如果一个 Candidate 或者 Leader 意识到它的任期号过时了,它会立刻转换为 Follower 状态。如果一台服务器收到的请求的任期号是过时的,那么它会拒绝此次请求。
Raft中的服务器通过远程过程调用(RPC)来通信,基本的 Raft 一致性算法仅需要 2 种 RPC。RequestVote RPC是 Candidate 在选举过程中触发的(5.2节),AppendEntries RPC 是 Leader 触发的,为的是复制日志条目和提供一种心跳(Heartbeat)机制(5.3节)。第7章加入了第三种 RPC 来在各个服务器之间传输快照(Snapshot)。如果服务器没有及时收到 RPC 的响应,它们会重试,并且它们能够并行的发出 RPC 来获得最好的性能。