5.3 日志复制
一旦选出了 Leader,它就开始接收客户端的请求。每一个客户端请求都包含一条需要被复制状态机(Replicated State Machine)执行的命令。Leader 把这条命令作为新的日志条目加入到它的日志中去,然后并行的向其它服务器发起 AppendEntries RPC,要求其它服务器复制这个条目。当这个条目被安全的复制之后(下面的部分会详细阐述),Leader 会将这个条目应用到它的状态机中并且会向客户端返回执行结果。如果 Follower 崩溃了或者运行缓慢或者是网络丢包了,Leader 会无限的重试 AppendEntries RPC(甚至在它向客户端响应之后),直到有的 Follower 最终存储了所有的日志条目。
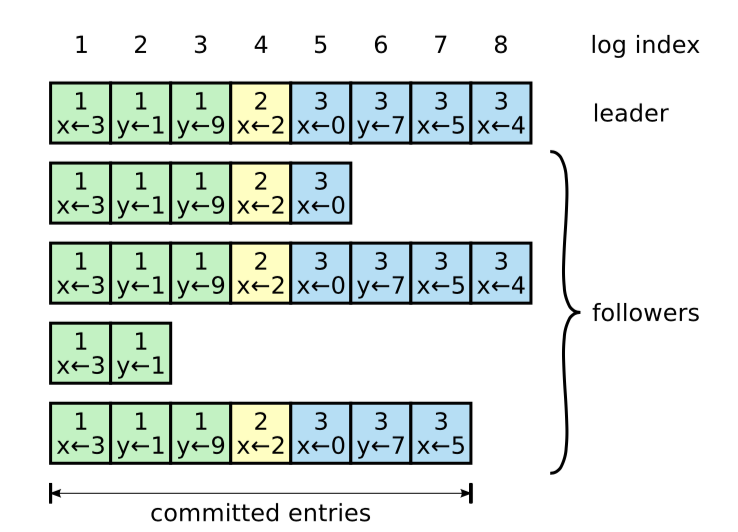
图-6:日志由有序编号的日志条目组成。每个日志条目包含它被创建时的任期号(每个方块中的数字),并且包含用于状态机执行的命令。如果一个条目能够被状态机安全执行,就被认为可以提交了。
日志就像 图-6 所示那样组织的。每个日志条目存储着一条被状态机执行的命令,以及当这条日志条目被 Leader 接收时的任期号。日志条目中的任期号用来检测在不同服务器上日志的不一致性,并且能确保 图-3 中的一些特性。每个日志条目也包含一个整数索引来表示它在日志中的位置。
Leader 决定什么时候将日志条目应用到状态机是安全的;这种条目被称为是已提交的(Committed)。Raft 保证可已提交
的日志条目是持久化的,并且最终会被所有可用的状态机执行。一旦被 Leader 创建的条目已经复制到了大多数的服务器上,这个条目就称为已提交的(例如,图-6 中的7号条目)。Leader 日志中之前的条目都是已提交的,包括由之前的 Leader 创建的条目。5.4节将会讨论,当 Leader 更替之后应用这条规则的微妙之处,并且也会讨论这种承诺(Commitment)的定义是安全的。Leader 跟踪记录它所知道的已提交的条目的最大索引值,并且这个索引值会包含在之后的 AppendEntries RPC 中(包括心跳中),为的是让其他服务器都知道这个条目已经提交。一旦一个 Follower 知道了一个日志条目已经是已提交的,它会将该条目应用至本地的状态机(按照日志顺序)。
我们设计了 Raft 日志机制来保证不同服务器上日志的一致性。这样做不仅简化了系统的行为使得它更可预测,并且也是保证安全性不可或缺的一部分。Raft 保证以下特性,并且也保证了 表-3 中的日志匹配原则(Log Matching Property):
- 如果在不同日志中的两个条目有着相同的索引和任期号,则它们所存储的命令是相同的。
- 如果在不同日志中的两个条目有着相同的索引和任期号,则它们之间的所有条目都是完全一样的。
第一条特性源于 Leader 在一个任期里,在给定的一个日志索引位置最多创建一条日志条目,同时该条目在日志中的位置也从来不会改变。第二条特性源于 AppendEntries 的一个简单的一致性检查。当发送一个 AppendEntries RPC 时,Leader 会把新日志条目紧接着之前的条目的索引位置和任期号都包含在里面。如果 Follower 没有在它的日志中找到相同索引和任期号的日志,它就会拒绝新的日志条目。这个一致性检查就像一个归纳步骤:一开始空的日志的状态一定是满足日志匹配原则的,一致性检查保证了当日志添加时的日志匹配原则。因此,只要 AppendEntries 返回成功的时候,Leader 就知道 Follower 的日志和它的是一致的了。
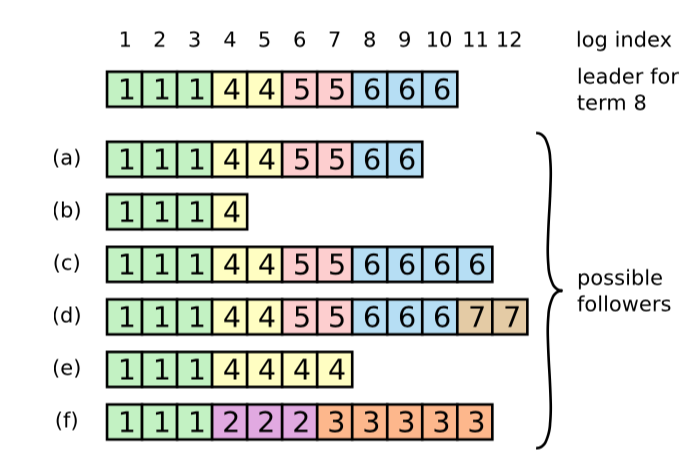
图-7:当最上面的 Leader 掌权之后,Follower 日志可能有以下情况(a~f)。一个格子表示一个日志条目;格子中的数字是它的任期。一个 Follower 可能会丢失一些条目(a, b);可能多出来一些未提交的条目(c, d);或者两种情况都有(e, f)。例如,场景f在如下情况下就会发生:如果一台服务器在任期2时是Leader并且向它的日志中添加了一些条目,然后在将它们提交之前就宕机了,之后它很快重启了,成为了任期3的 Leader,又向它的日志中添加了一些条目,然后在任期2和任期3中的条目提交之前它又宕机了,并且几个任期内都一直处于宕机状态。
在一般情况下,Leader 和 Follower 的日志保持一致,因此 AppendEntries 一致性检查通常不会失败。然而,Leader 的崩溃会导致日志不一致(旧的 Leader 可能没有完全复制完日志中的所有条目)。这些不一致会导致一系列 Leader 和 Follower 崩溃。图-7 阐述了一些 Follower 可能和新的 Leader 日志不同的情况。一个 Follower 可能会丢失掉 Leader 上的一些条目,也有可能包含 Leader 没有的一些条目,也有可能两者都会发生。丢失的或者多出来的条目可能会持续多个任期。
在Raft算法中,Leader 通过强制 Follower 复制它的日志来处理日志的不一致。这就意味着,在 Follower 上的冲突日志会被领导者的日志覆盖。5.4节会说明当添加了一个额外的限制之后这是安全的。
为了使得 Follower 的日志和自己的一致,Leader 需要找到 Follower 与它的日志一致的地方,然后删除 Follower 在该位置之后的条目,然后将自己在该位置之后的条目发送给 Follower。这些操作都在 AppendEntries RPC 进行一致性检查时完成。Leader 给每一个Follower 维护了一个 nextIndex,它表示 Leader 将要发送给该追随者的下一条日志条目的索引。当一个 Leader 开始掌权时,它会将 nextIndex 初始化为它的最新的日志条目索引数+1(图-7 中的11)。如果一个 Follower 的日志和 Leader 的不一致,AppendEntries 一致性检查会在下一次 AppendEntries RPC 时返回失败。在失败之后,Leader 会将 nextIndex 递减然后重试 AppendEntries RPC。最终 nextIndex 会达到一个 Leader 和 Follower 日志一致的地方。这时,AppendEntries 会返回成功,Follower 中冲突的日志条目都被移除了,并且添加所缺少的上了 Leader 的日志条目。一旦 AppendEntries 返回成功,Follower 和 Leader 的日志就一致了,这样的状态会保持到该任期结束。
如果需要的话,算法还可以进行优化来减少 AppendEntries RPC 失败的次数。例如,当拒绝一个 AppendEntries 请求时,Follower 可以记录下冲突日志条目的任期号和自己存储那个任期的最早的索引。通过这些信息,Leader 能够直接递减 nextIndex 跨过那个任期内所有的冲突条目;这样的话,一个冲突的任期需要一次AppendEntries RPC,而不是每一个冲突条目需要一次 AppendEntries RPC。在实践中,我们怀疑这种优化是否是必要的,因为 AppendEntries 一致性检查很少失败并且也不太可能出现大量的日志条目不一致的情况。
通过这种机制,一个 Leader 在掌权时不需要采取另外特殊的方式来恢复日志的一致性。它只需要使用一些常规的操作,通过响应 AppendEntries 一致性检查的失败能使得日志自动的趋于一致。一个 Leader 从来不会覆盖或者删除自己的日志(表-3 中的 Leader 只增加原则)。
这个日志复制机制展示了在第2章中阐述的所希望的一致性特性:Raft 能够接受,复制并且应用新的日志条目只要大部分的服务器是正常的。在通常情况下,一个新的日志条目可以在一轮 RPC 内完成在集群的大多数服务器上的复制;并且一个速度很慢的 Follower 并不会影响整体的性能。